2.8 Décomposition de la variance
2.8.1 Coefficient de détermination
Considérons l’exemple dans lequel on régresse, dans la population des salariés étatsuniens, le salaire horaire sur l’éducation mesurée en années passées dans le système scolaire. On cherche donc à écrire le salaire comme la somme d’une fonction affine de l’éducation d’une part, c’est-à-dire la valeur prédite du salaire, et d’une variable aléatoire de moyenne nulle et non-corrélée à l’éducation d’autre part. Cette décomposition a des conséquences quant à la variance du salaire, que l’on peut utiliser pour quantifier sa dispersion. En effet, la variance du salaire peut s’écrire comme la somme de trois termes :
- la variance du salaire prédit ;
- la variance du résidu ;
- le double de la covariance du résidu et de la valeur prédite.
Or le salaire prédit est une fonction affine de l’éducation. Par conséquent, la covariance du résidu et du salaire prédit est nulle. La variance du salaire horaire est donc la somme de la variance du salaire prédit et de la variance du résidu.
Le rapport de la variance du salaire prédit sur la variance du salaire réalisé est donc toujours compris entre 0 et 1. Elle s’interprète parfois comme la part de la variance du salaire qui s’explique par la dispersion du niveau d’éducation, par opposition à la part de cette variance qui s’explique par la variation des résidus.
Définition
Cette quantité est souvent notée \(R^2\), et on l’appelle le coefficient de détermination.
Plus généralement, étant donnée une variable aléatoire réelle \(Y\), et une variable aléatoire multidimensionnelle de dimension \(d\) notée \(X\), tous les résultats précédents autorisent, dans le cas où la condition de rang est respectée, à considérer le vecteur \(\beta\) et les variables aléatoires \(\hat{Y}\) et \(\epsilon\) tels que \(Y=\hat{Y} + \epsilon\) avec \(\hat{Y}=X'\beta\), \(\mathbb{E}[\epsilon]=0\) et \(\mathbb{E}[X\epsilon]=0\). Cette écriture permet de décomposer très simplement la variance de la variable \(Y\). En effet, comme \(\mathcal{C}(X_i, \epsilon)\) pour toutes les dimensions \(i\) dans \(\{1, \dots, d\}\), on a \(\mathcal{V}(Y) = \mathcal{V}(\hat{Y}) + \mathcal{V}(\epsilon)\). Ainsi la quantité \(\frac{\mathcal{V}(\hat{Y})}{\mathcal{V}(Y)}\) est toujours comprise entre 0 et 1. La définition précédente revient donc à poser :
\[R^2:=\frac{\mathcal{V}(\hat{Y})}{\mathcal{V}(Y)}\]
Dans le cas unidimensionnel, cette quantité correspond au carré de la corrélation \(\rho_{XY}\). Le fragment de code suivant permet de le vérifier à partir des données du CPS.
library(AER,
quietly=TRUE)
library(data.table,
quietly=TRUE)
#On charge dans un premier temps les données du CPS 1985
data("CPS1985")
CPS<-data.table(CPS1985)
#On régresse le salaire horaire sur l'éducation
reg_wage_educ<-lm(wage ~ education,
data=CPS)
#Le coefficient de détermination apparaît dans les sorties standard pour les
# régressions linéaires
summary(reg_wage_educ)##
## Call:
## lm(formula = wage ~ education, data = CPS)
##
## Residuals:
## Min 1Q Median 3Q Max
## -7.911 -3.260 -0.760 2.240 34.740
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.74598 1.04545 -0.714 0.476
## education 0.75046 0.07873 9.532 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.754 on 532 degrees of freedom
## Multiple R-squared: 0.1459, Adjusted R-squared: 0.1443
## F-statistic: 90.85 on 1 and 532 DF, p-value: < 2.2e-16#On vérifie que la variance du salaire est bien égale à la somme de la variance
# du salaire prédit et de la variance des résidus
all.equal(var(CPS$wage),
var(reg_wage_educ$fitted.values)+var(reg_wage_educ$residuals))## [1] TRUE#On vérifie que le R² estimé par R est bien le rapport de la variance du salaire
# prédit et de la variance du salaire réalisé
all.equal(summary(reg_wage_educ)$r.squared,
var(reg_wage_educ$fitted.values)/var(CPS$wage))## [1] TRUE#On vérifie enfin que le coefficient de détermination est bien égal au carré de
# la corrélation entre le salaire et l'éducation
all.equal(summary(reg_wage_educ)$r.squared,
cor(CPS$wage,
CPS$education)^2)## [1] TRUEAvertissement
Le concept d’explication invoqué ici n’a pas en général de signification causale. Comme cela est établi dans le paragraphe précédent sur le cas unidimensionnel, le coefficient de détermination n’a aucun autre contenu que d’être une mesure de corrélation entre la variable dépendante et les variables indépendantes. Il est donc dénué de sens dans le cas général de chercher à fonder une interprétation causale, ou son rejet, sur la valeur de cette quantité.
En fait, il serait plus correct lorsque l’on parle du coefficient de détermination de dire que 14.6% de la variance du salaire horaire correspond par des différences de salaire entre salariés de niveaux d’éducation différents, et les 85.4% restants à des différences entre salariés ayant le même niveau d’éducation, que de parler d’explication qui porte toujours cette ambiguité sur le sens causal que l’on donne à la régression11.
À retenir
Lorsque l’on cherche à répondre à une question causale au moyen d’une régression linéaire, l’attention est plus souvent portée sur les coefficients que sur la valeur prédite. De ce fait, le coefficient de détermination a généralement peu d’intérêt dans ce contexte. En fait, il est même généralement préférable de ne pas le reporter, quand bien même il apparaît dans l’affichage par défaut des résultats des régressions linéaires pour la plupart des logiciels statistiques.
2.8.2 Une interprétation fréquente du coefficient de détermination
Au-delà de cette question d’interprétation causale, le coefficient de détermination est parfois utilisé comme une mesure de qualité du modèle de régression. Cela ne va pas sans poser de difficulté, dont la moindre n’est pas la polysémie et l’ambiguité du mot “qualité”. Comme le coefficient de détermination est purement une mesure de corrélation, il ne peut en aucun cas s’agir d’une qualité qui se rapporte à l’interprétation causale des coefficients de régression.
On a vu que la régression linéaire par la méthode des moindres carrés ordinaires pouvait s’interpréter comme la recherche de la meilleure approximation de la variable dépendante \(Y\) par une fonction affine des variables indépendantes \(X\). En ce sens, on peut considérer que la qualité d’une régression linéaire pourrait être mesurée par la variance du résidu \(\epsilon\), c’est-à-dire par la dispersion de la différence entre \(Y\) et cette fonction affine des variables indépendantes.
Une régression serait alors considérée comme de meilleure qualité si cette dispersion est faible (relativement à celle de \(Y\)) : dans ce cas, pour de nombreux individus dans la population d’intérêt, la valeur prédite par la fonction affine des variables indépendantes se trouve être très proche de la valeur réalisée de \(Y\). Inversement, une régression serait de qualité faible lorsque cette dispersion est forte, c’est-à-dire lorsque pour de nombreux individus de la population la valeur prédite se trouve très loin de la valeur réalisée de \(Y\).
Ce qui précède permet d’établir que le coefficient de détermination \(R^2:=\frac{\mathcal{V}(\hat{Y})}{\mathcal{V}(Y)}\) peut également s’écrire \(R^2=1-\frac{\mathcal{V}(\epsilon)}{\mathcal{V}(Y)}\). De la sorte, lorsque le coefficient de détermination est proche de 1, la variable dépendante \(Y\) est en un sens bien approximée par la fonction affine des variables indépendantes. Inversement, lorsqu’il est proche de 0, la valeur de la variable dépendante \(Y\) est souvent éloignée de la valeur prédite par la fonction affine des variables indépendantes donnée par la régression. L’exemple suivant permet de visualiser deux régressions linéaires sur des données simulées, l’un avec un coefficient de détermination proche de 1, l’autre avec un coefficient de détermination plus proche de 0.
library(data.table,
quietly=TRUE)
library(ggplot2,
quietly=TRUE)
set.seed(20220921)
#On simule 10000 observations de la variable indépendantesà partir d'une loi
# normale centrée réduite, et on fait de même pour créer une autre variable
# qui va jouer le rôle de résidu
simuldat<-data.table(c(rnorm(10000)),
c(rnorm(10000)))
colnames(simuldat)<-c("x",
"epsilon")
#On crée deux variables dépendantes différentes à partir de cette variable
# indépendantes. La seule différence entre ces deux variables tient à la
# dispersion du résidu : la variance du résidu est 9 fois plus grande pour
# y2 qu'elle n'est pour y1
simuldat[,
c("y1",
"y2"):=list(1+2*x+epsilon,
1+2*x+3*epsilon)]
#On calcule le coefficient de détermination dans les deux cas
r2_y1<-round(summary(lm(y1~x,
data=simuldat))$r.squared,
digits=2)
r2_y2<-round(summary(lm(y2~x,
data=simuldat))$r.squared,
digits=2)
#On visualise le nuage de points et la droite de régression dans les deux cas
nuage<-ggplot(data=simuldat,
aes(x=x))+
theme_classic()+#supprime l'arrière-plan gris par défaut
coord_cartesian(xlim=c(-2.5,2.5),
ylim=c(-7.5,12.5))+#choix d'échelle des axes
ylab("Variable dépendante")+#titre des axes
xlab("Variable indépendante")+
theme(text=element_text(size=32),#taille du texte
strip.text.x = element_text(size=32),
panel.grid.minor = element_line(colour="lightgray",
linewidth=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
linewidth=0.01))
nuage+
geom_point(aes(y=y1),
alpha=0.2,
size=5)+#le nuage de points
geom_line(color="red",
linewidth=3,
aes(y=1+2*x))+#la droite de régression
annotate("text",
x=-2,
y=10,
label=paste0("R² = ",
r2_y1),
size=8)#afficher le coefficient de détermination
nuage+
geom_point(aes(y=y2),
alpha=0.2,
size=5)+#le nuage de points
geom_line(color="red",
linewidth=3,
aes(y=1+2*x))+#la droite de régression
annotate("text",
x=-2,
y=10,
label=paste0("R² = ",
r2_y2),
size=8)#afficher le coefficient de détermination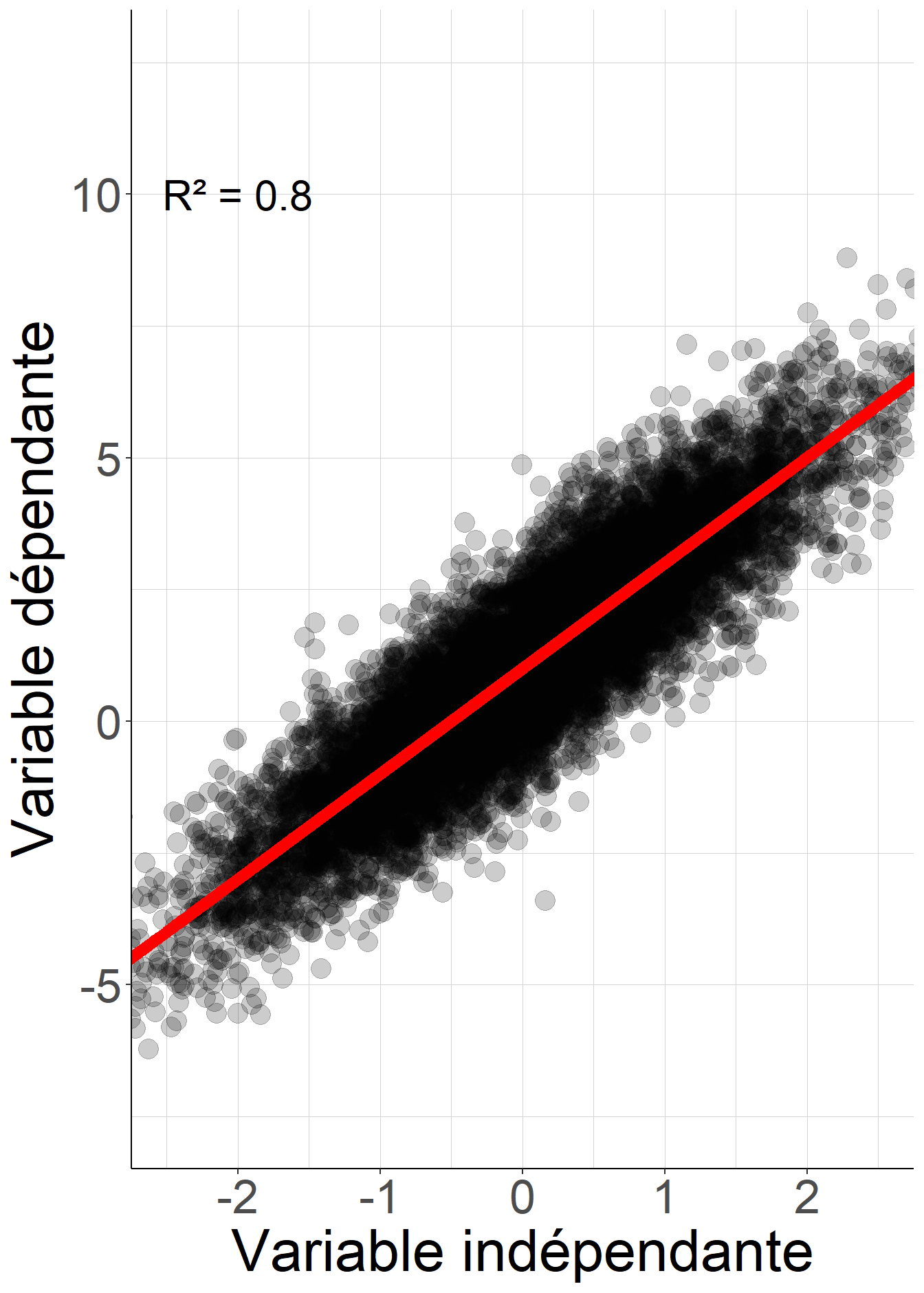
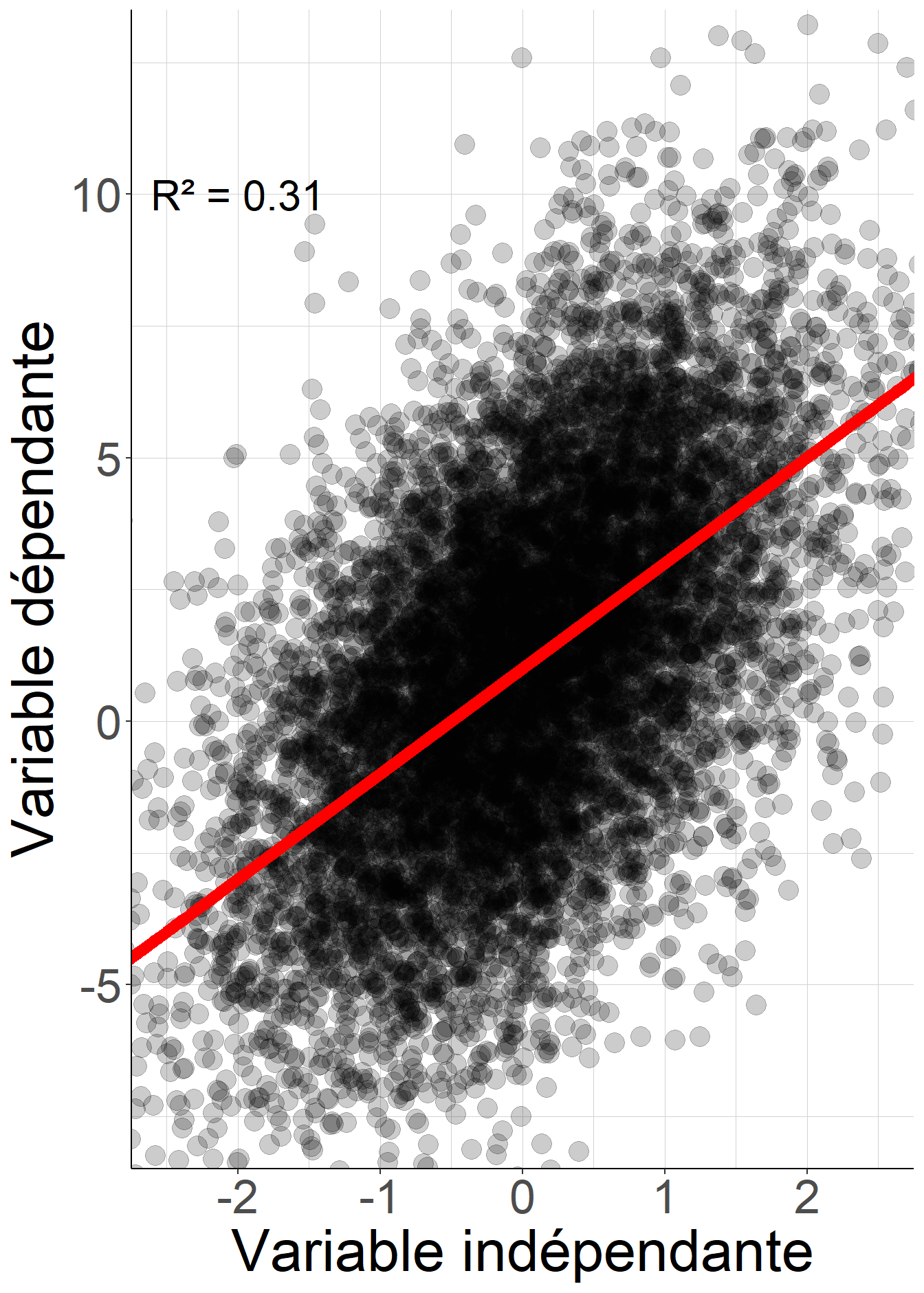
Figure 2.8: Lorsque le coefficient de détermination est proche de 1, la valeur prédite de la variable dépendante, représentée par la droite rouge, est souvent proche de sa valeur réalisée, représentée par les points noirs. Au contraire, lorsque le coefficient de détermination est proche de 0, ces deux valeurs sont souvent éloignées
2.8.3 Problèmes liés à l’interprétation usuelle du coefficient de détermination
On a vu que le concept de qualité mesuré par le coefficient de détermination n’a rien à voir avec la pertinence de l’interprétation causale des coeffiicients de régression. Par ailleurs, la valeur du coefficient de détermination ne dit rien de la légitimité et de l’intérêt d’une régression linéaire. Cette légitimité repose exclusivement sur le respect de la condition de rang : les hypothèses sous lesquelles les coefficients de régression peuvent être estimés ne dépendent en aucun cas de ce que le coefficient de détermination est faible ou élevé.
En fait, le coefficient de détermination n’est que de peu d’intérêt aussi longtemps que l’on s’intéresse aux valeurs de coefficients de la régression linéaire. Ainsi, le fait qu’il soit plus élevé, ou plus faible n’a pas d’incidence sur l’interprétation des coefficients de la régression. En réalité, il n’est d’intérêt que dans le cas où l’intérêt porte sur la valeur prédite, c’est-à-dire sur la variable \(\alpha + X'\beta\), ou en d’autres termes sur l’approximation de la variable dépendante par une fonction affine des variables indépendantes.
En particulier, en sciences sociales quantitatives, il est rare de trouver des valeurs de coefficient de détermination très élevées lorsque l’on n’est pas dans des cas où la variable dépendante et les variables indépendantes sont évidemment très corrélées (caricaturalement dans le cas où l’on régresse la taille du pied gauche sur la taille du pied droit). Le fragment de code suivant estime par exemple le coefficient de détermination atteint pour différentes équations de salaire à partir des données du CPS. Même avec les dix variables indépendantes fournies par les données, le coefficient de détermination atteint tout au plus 33%.
library(AER,
quietly=TRUE)
library(data.table,
quietly=TRUE)
#On charge dans un premier temps les données du CPS 1985
data("CPS1985")
CPS<-data.table(CPS1985)
#On tente plusieurs régressions en augmentant progressivement le nombre de
# variables indépendantes pour finir par prendre toutes celles disponibles
reg_coeff_determ<-function(nbrcov){
reg<-lm(as.formula(paste0("wage ~ ",
paste0(colnames(CPS)[2:(1+nbrcov)],
#sélectionne les nbrcov premières variables
# indépendantes à droite de wage dans la table
collapse="+"))),
data=CPS)
output<-list(as.formula(paste0("wage ~ ",
paste0(colnames(CPS)[2:(1+nbrcov)],
collapse="+"))),
#on récupère l'appel de la régression
summary(reg)$r.squared)#on récupère le R² de la régression
names(output)<-c("appel",
"coeff_determination")
output
}
#On applique progressivement cette fonction à un nombre croissant de variables
# indépendantes avec un incrément de 1
lapply(1:(ncol(CPS)-1),
reg_coeff_determ)## [[1]]
## [[1]]$appel
## wage ~ education
## <environment: 0x00000213e97eb410>
##
## [[1]]$coeff_determination
## [1] 0.1458645
##
##
## [[2]]
## [[2]]$appel
## wage ~ education + experience
## <environment: 0x00000213e97a2250>
##
## [[2]]$coeff_determination
## [1] 0.2020248
##
##
## [[3]]
## [[3]]$appel
## wage ~ education + experience + age
## <environment: 0x00000213fcea8958>
##
## [[3]]$coeff_determination
## [1] 0.2020253
##
##
## [[4]]
## [[4]]$appel
## wage ~ education + experience + age + ethnicity
## <environment: 0x00000213fce4a510>
##
## [[4]]$coeff_determination
## [1] 0.2051386
##
##
## [[5]]
## [[5]]$appel
## wage ~ education + experience + age + ethnicity + region
## <environment: 0x00000213fcdbcdb8>
##
## [[5]]$coeff_determination
## [1] 0.2098587
##
##
## [[6]]
## [[6]]$appel
## wage ~ education + experience + age + ethnicity + region + gender
## <environment: 0x00000213fcd29080>
##
## [[6]]$coeff_determination
## [1] 0.2622824
##
##
## [[7]]
## [[7]]$appel
## wage ~ education + experience + age + ethnicity + region + gender +
## occupation
## <environment: 0x00000213fcc6e7c0>
##
## [[7]]$coeff_determination
## [1] 0.3083759
##
##
## [[8]]
## [[8]]$appel
## wage ~ education + experience + age + ethnicity + region + gender +
## occupation + sector
## <environment: 0x00000213fcb7dd10>
##
## [[8]]$coeff_determination
## [1] 0.3125551
##
##
## [[9]]
## [[9]]$appel
## wage ~ education + experience + age + ethnicity + region + gender +
## occupation + sector + union
## <environment: 0x00000213fca83cd8>
##
## [[9]]$coeff_determination
## [1] 0.3257951
##
##
## [[10]]
## [[10]]$appel
## wage ~ education + experience + age + ethnicity + region + gender +
## occupation + sector + union + married
## <environment: 0x00000213fc90ec50>
##
## [[10]]$coeff_determination
## [1] 0.3264908Enfin, certains travaux peuvent utiliser le coefficient de détermination comme une façon de quantifier la pertinence du choix de se restreindre à approcher la variable indépendante \(Y\) par une fonction affine des variables indépendantes \(X\), plutôt que par une fonction plus générale (voir B.1). Cet usage n’est pas totalement injustifié : en effet, si le coefficient de détermination est égal à 1, alors la variance des résidus est égale à 0, et donc on peut écrire \(Y\) comme une fonction affine des variables indépendantes.
Lorsque le coefficient de détermination est plus faible en revanche, cette interprétation peut rapidement devenir problématique. En effet, un coefficient de détermination faible ne signifie pas que chercher l’approximation de \(Y\) dans un ensemble plus général de fonctions de \(X\), c’est-à-dire en somme considérer l’espérance conditionnelle plutôt que la régression linéaire donnerait une approximation bien meilleure de la variable dépendante \(Y\). Le fragment de code suivant illustre ce fait à partir de données simulées
library(data.table,
quietly=TRUE)
library(ggplot2,
quietly=TRUE)
set.seed(20220921)
#On simule 10000 observations de la variable indépendantes à partir d'une loi
# normale centrée réduite, et on fait de même pour créer une autre variable
# qui va jouer le rôle de résidu
simuldat<-data.table(c(rnorm(10000)),
c(rnorm(10000)))
colnames(simuldat)<-c("x",
"epsilon")
#On crée à partir de ces deux variables deux variables dépendantes y1 et y2. La
# première s'écrit la somme d'une fonction affine de x plus un résidu
# indépendant de x. La seconde s'écrit comme la somme d'une fonction
# quadratique de x et d'une résidu indépendant de x.
#Ainsi, l'espérance conditionnelle E[y1 | x] est une fonction affine de x,
# tandis que l'espérance conditionnelle E[y2 | x] est une fonction quadratique
# de x.
simuldat[,
c("y1",
"y2"):=list(1+2*x+2.4*epsilon,
5+2*x-1.5*x^2+epsilon)]
#On régresse les deux variables dépendantes sur la variable indépendante x
reg1<-lm(y1~x,
data=simuldat)
reg2<-lm(y2~x,
data=simuldat)
#On visualise les nuages de points, ainsi que les droites de régression et
# l'espérance conditionnelle pour les deux cas considérés.
nuage<-ggplot(data=simuldat,
aes(x=x))+
theme_classic()+#supprime l'arrière-plan gris par défaut
coord_cartesian(xlim=c(-2.5,2.5),
ylim=c(-7.5,12.5))+#choix d'échelle des axes
ylab("Variable dépendante")+#titre des axes
xlab("Variable indépendante")+
theme(text=element_text(size=32),#taille du texte
strip.text.x = element_text(size=32),
panel.grid.minor = element_line(colour="lightgray",
linewidth=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
linewidth=0.01))
nuage+
geom_point(aes(y=y1),
alpha=0.2,
size=5)+#le nuage de points
geom_line(color="red",
linewidth=3,
aes(y=reg1$coefficients["(Intercept)"]+
reg1$coefficients["x"]*x))+#la droite de régression
annotate("text",
x=-2,
y=10,
label=paste0("R² = ",
round(summary(reg1)$r.squared,
digits=2)),
size=8)#afficher le coefficient de détermination
nuage+
geom_point(aes(y=y2),
alpha=0.2,
size=5)+#le nuage de points
geom_line(color="red",
linewidth=3,
aes(y=reg2$coefficients["(Intercept)"]+
reg2$coefficients["x"]*x))+#la droite de régression
geom_line(aes(y=5+2*x-1.5*x^2),
color="red",
linetype="dashed",
linewidth=3)+#l'espérance conditionnelle
annotate("text",
x=-2,
y=10,
label=paste0("R² = ",
round(summary(reg2)$r.squared,
digits=2)),
size=8)#afficher le coefficient de détermination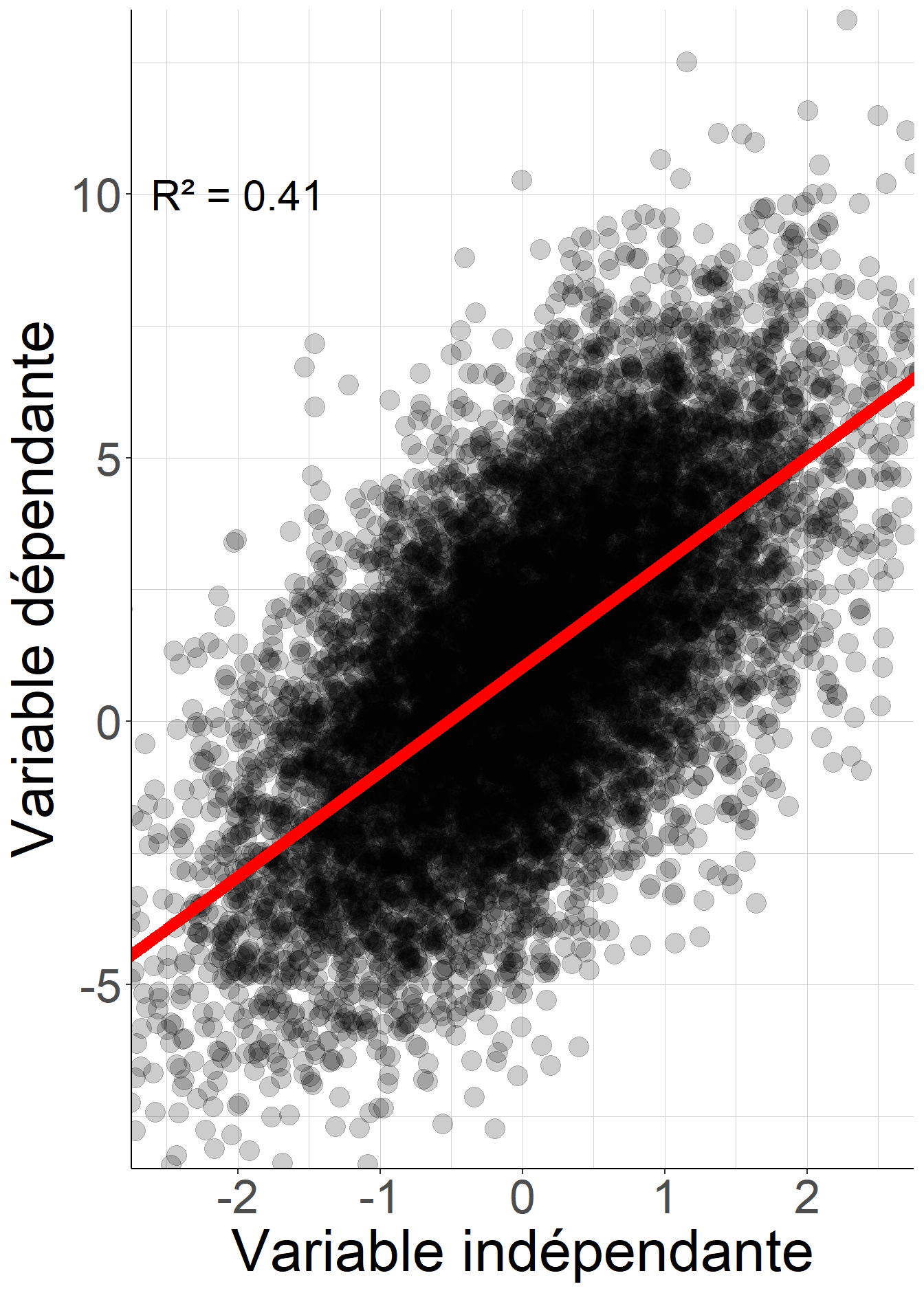
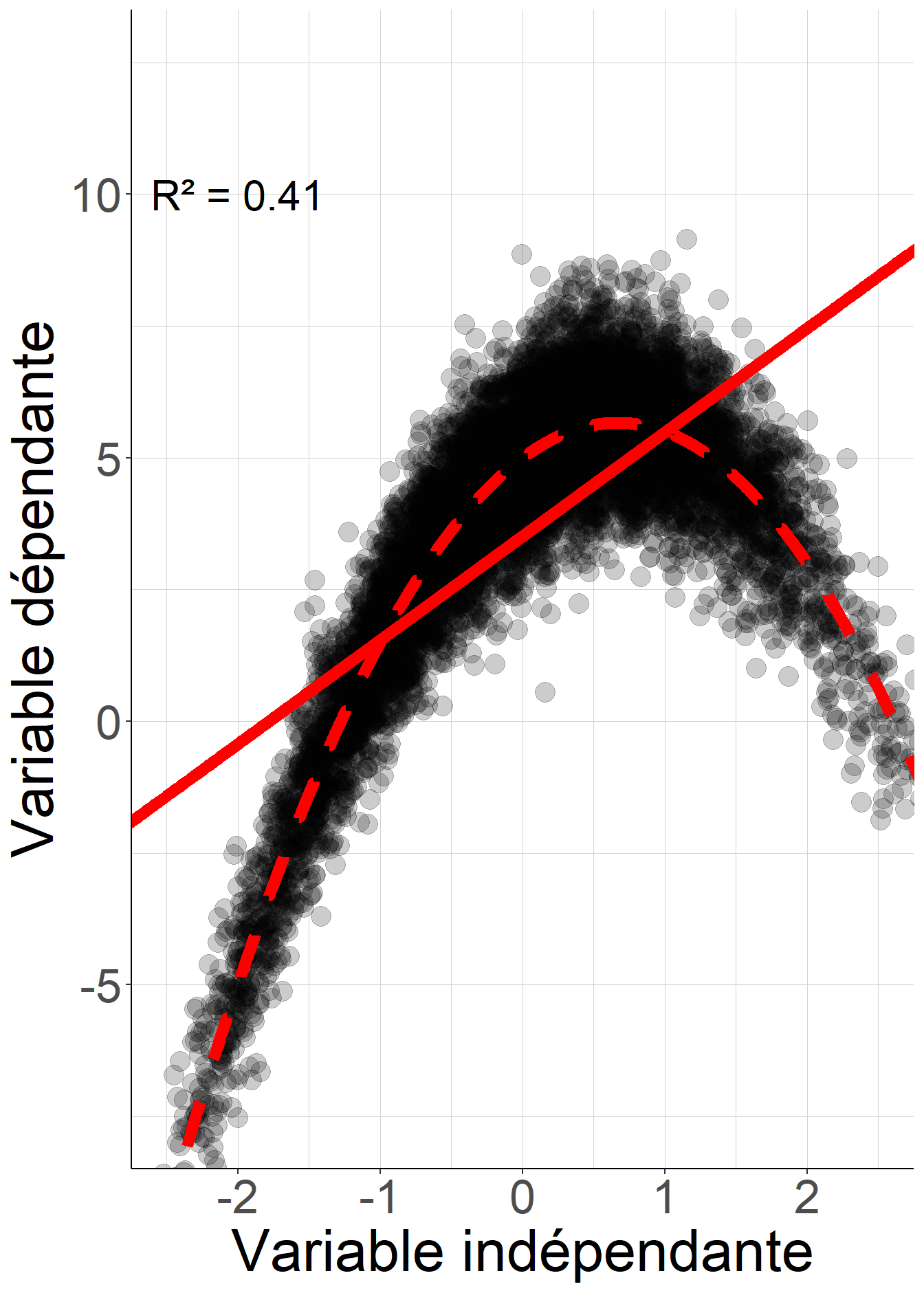
Figure 2.9: Pour les deux variables dépendantes simulées, la régression linéaire de la variable dépendante sur la variable indépendante le même coefficient de détermination. Pour autant, dans le premier cas l’espérance conditionnelle coïncide avec la droite de régression : il n’y a pas de gain à vouloir approximer la variable dépendante par une fonction plus générale de la variable indépendante. Au contraire, dans le second cas l’espérance conditionnelle, représentée par la courbe en pointillés rouges, est très différente de la droite de régression, représentée par la droite rouge en trait continu, de sorte que chercher une approximation de la variable dépendante par une fonction plus générale de la variable indépendante aboutirait à des valeurs prédites plus proches des valeurs réalisées.