5.1 Une estimation apparemment simple
Le travail de Gerber et Green (2000) se concentre sur une expérience aléatoire contrôlée destinée à étudier l’effet de différentes interventions, et notamment des contacts téléphoniques auprès d’électeurs potentiels résidant à New Haven, sur le taux de participation aux élections de novembre 1998. Un des résultats surprenants de leur travail suggèrerait que le contact téléphonique réduirait le taux de participation de plusieurs points de pourcentage.
Dans son réexamen des données de l’expérience, Imai (2005) exhibe plusieurs éléments qui correspondent à des échecs dans la randomisation nécessaire à la bonne interprétation des résultats de l’expérience. Entre autre choses, il montre que la probabilité de recevoir un appel téléphonique, qui correspond à l’intervention étudiée, diffère selon les quartiers de New Haven. Le fragment de code suivant permet de visualiser cette variabilité de la proportion de personnes ayant reçu un appel téléphonique d’un quartier à l’autre.
library(data.table)
library(ggplot2)
library(Matching)
#On récupère les données et on convertit en data.table
data(GerberGreenImai)
GerberGreenImai<-data.table(GerberGreenImai)
#On estime la probabilité d'avoir reçu un appel téléphonique pour chaque
# quartier de New Haven
proba_appel<-GerberGreenImai[,
list(prob_phone_call=mean(PHN.C1),
taille=.N),
by=c("WARD")]
#Pour visualiser les probabilités pour chaque quartier
ggplot(data=proba_appel,
aes(x=WARD,
y=prob_phone_call))+
geom_point(aes(size=taille/nrow(GerberGreenImai)),
alpha=0.5)+
theme_classic()+
scale_y_continuous(labels = scales::percent)+
scale_size(name="Part dans la \npopulation de \nNew Haven",
labels=scales::percent)+
xlab("Identifiant du quartier")+
ylab("Part des individus ayant \nreçu un appel")+
theme(text=element_text(size=16),#taille du texte
legend.title=element_text(size=12),
legend.text=element_text(size=12),
axis.text.x = element_text(size=10),
panel.grid.minor = element_line(colour="lightgray",
size=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
size=0.01))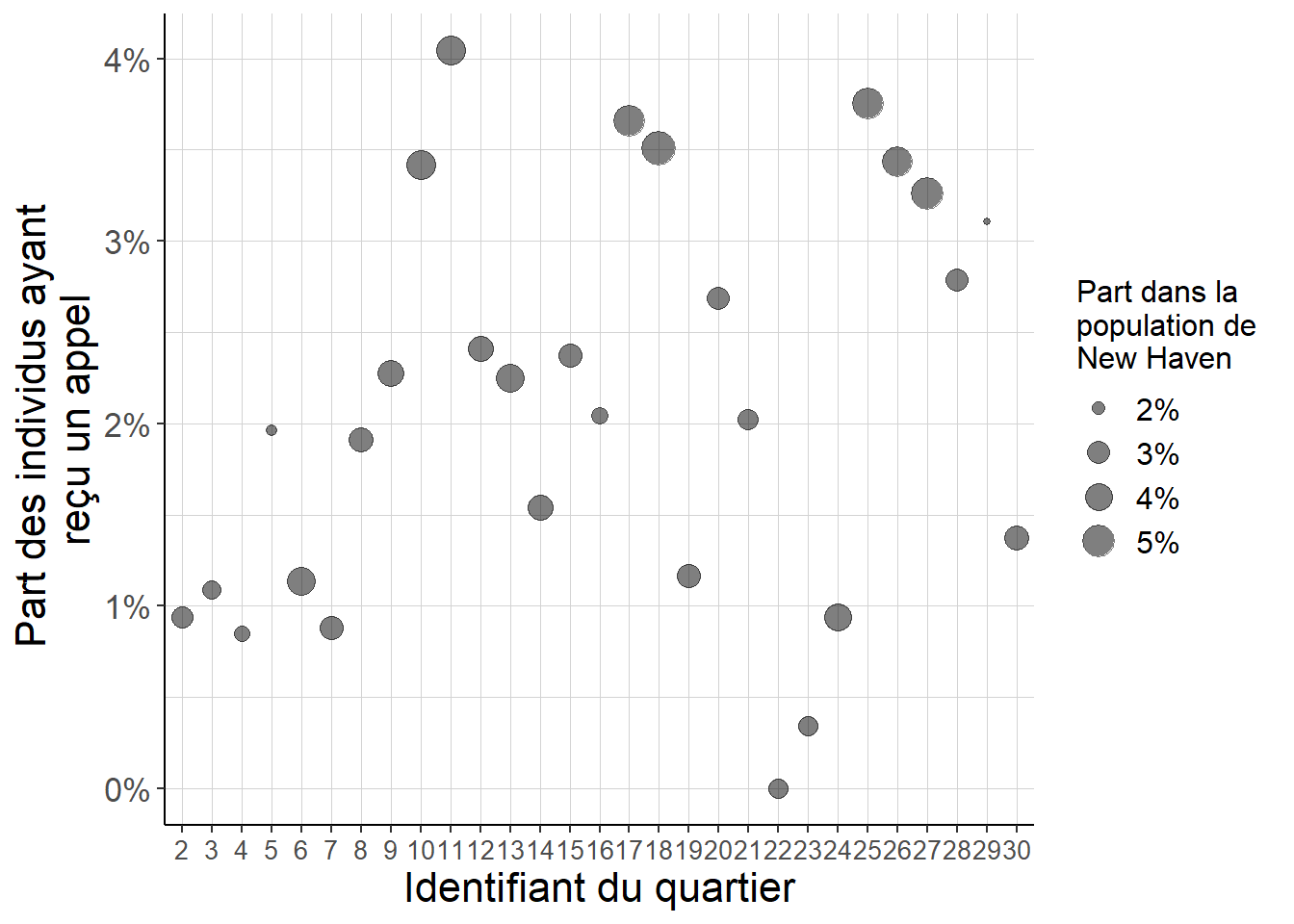
Figure 5.1: La probabilité de recevoir un appel diffère d’un quartier à l’autre, ce qui montre que lorsque l’on raisonne au niveau de New Haven prise toute entière, la randomisation est imparfaite.
On va supposer dans un premier temps, pour les besoins de la démonstration, qu’il s’agit là du seul véritable problème. En d’autres termes, on suppose qu’à l’échelle de chaque quartier, la randomisation est correcte, de sorte que l’on est bien dans le cas d’une expérience aléatoire stratifiée, c’est-à-dire d’un ensemble de petites expériences aléatoires menées au niveau de chaque quartier, mais avec des probabilités de recevoir un appel téléphonique différentes d’un quartier à l’autre. On est alors en droit de conditionner par le quartier de résidence, c’est-à-dire de faire la comparaison entre individus qui on reçu un appel téléphonique et individus qui n’ont pas reçu un tel appel, et qui habitent tous le même quartier.
#On estime les probabilités de vote, selon que l'on a reçu un appel ou non,
# quartier par quartier
proba_vote<-GerberGreenImai[,
list(prob_vote_traite=sum(VOTED98*PHN.C1)/
sum(PHN.C1),
prob_vote_controle=sum(VOTED98*(1-PHN.C1))/
sum(1-PHN.C1),
taille=.N),
by=c("WARD")]
#Comme à l'intérieur de chaque quartier, on suppose que la randomisation est
# correcte, on peut en tirer un effet moyen spécifique à chaque quartier
proba_vote[,
effet_moyen:=prob_vote_traite-prob_vote_controle]
#L'effet causal moyen sur tout New Haven est la moyenne des effets moyens dans
# chaque quartier (quand on pondère par la taille du quartier)
ATE<-proba_vote[!is.na(effet_moyen),
sum(effet_moyen*taille)/
sum(taille)]
#Pour visualiser les effets moyens pour chaque quartier
ggplot(data=proba_vote[!is.na(effet_moyen)],
aes(x=WARD,
y=effet_moyen*100))+
geom_point(aes(size=taille/nrow(GerberGreenImai)),
alpha=0.5)+
geom_hline(yintercept = as.numeric(ATE)*100,
color="red",
size=3)+
theme_classic()+
scale_size(name="Part dans la \npopulation de \nNew Haven",
labels=scales::percent)+
xlab("Identifiant du quartier")+
ylab(paste0("Effet causal moyen de l'appel \ntéléphonique sur",
"la participation \nélectorale (en p.p)"))+
theme(text=element_text(size=16),#taille du texte
legend.title=element_text(size=12),
legend.text=element_text(size=12),
axis.text.x = element_text(size=10),
panel.grid.minor = element_line(colour="lightgray",
size=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
size=0.01))
Figure 5.2: Lorsque l’on suppose qu’au niveau de chaque quartier, on est bien face à une expérience aléatoire contrôlée, on peut estimer l’effet causal moyen pour chacun de ces quartiers en comparant simplement les personnes qui ont ou qui n’ont pas reçu un appel les incitant à voter. L’effet causal moyen au niveau de New Haven prise toute entière, représenté par la droite horizontale rouge, est égal à la moyenne de ces effets moyens pris quartier par quartier, représentés par l’ordonnée de chaque point, avec des poids proportionnels à la taille de chaque quartier.