2.4 La régression linéaire simple est une moyenne de comparaisons deux à deux
Considérons un monde fictif dans lequel il existe seulement deux niveaux d’éducation possibles lorsque l’on mesure l’éducation en durée passée dans le système scolaire – 12 ans pour le niveau baccalauréat, et 15 ans pour le niveau licence – et où le salaire offert sur le marché du travail ne dépend que de ce niveau d’éducation – 10$ de l’heure pour les détenteurs du baccalauréat et 15$ de l’heure pour les détenteurs d’une licence –, alors on peut facilement estimer la pente de la droite représentant la fonction qui associe le salaire à l’éducation. En effet, il suffit pour cela de diviser la différence de salaire entre les deux groupes définis par l’éducation par la différence de durée passée dans le système scolaire : la valeur est de 1.67$ par heure pour chaque année d’éducation supplémentaire. Le fragment de code précédent permet de visualiser cet exemple fictif.
En d’autres termes, dans ce monde fictif, comparer entre eux n’importe quel couple de salariés dont le niveau d’éducation diffère – ce qui implique ici que l’un a passé 12 années dans le système scolaire et l’autre 15 – permet de retrouver le coefficient qui porte sur la variable d’éducation dans la régression du salaire horaire sur l’éducation.
library(AER,
quietly=TRUE)
library(data.table,
quietly=TRUE)
library(ggplot2,
quietly=TRUE)
#On crée les données correspondant à ce monde fictifs
fict_education_salaire<-data.table(c(12,15),
c(10,15))
colnames(fict_education_salaire)<-c("education",
"salaire")
#Visualisation du nuage de point et de la droite qui joint ces points
ggplot(data=fict_education_salaire,
aes(x=education,
y=salaire))+
geom_point(color="black",
size=5,
alpha=0.2,
aes(x=education))+#nuage de points
theme_classic()+#supprime l'arrière-plan gris par défaut
coord_cartesian(ylim=c(-5,30))+#choix d'échelle des axes
ylab("Salaire horaire ($ par heure)")+#titre des axes
xlab("Années d'éducation")+
theme(text=element_text(size=16),#taille du texte
strip.text.x = element_text(size=16),
panel.grid.minor = element_line(colour="lightgray",
linewidth=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
linewidth=0.01))+
geom_line(color="red",
linewidth=3,
aes(x=education,
y=-10+
5/3*
education))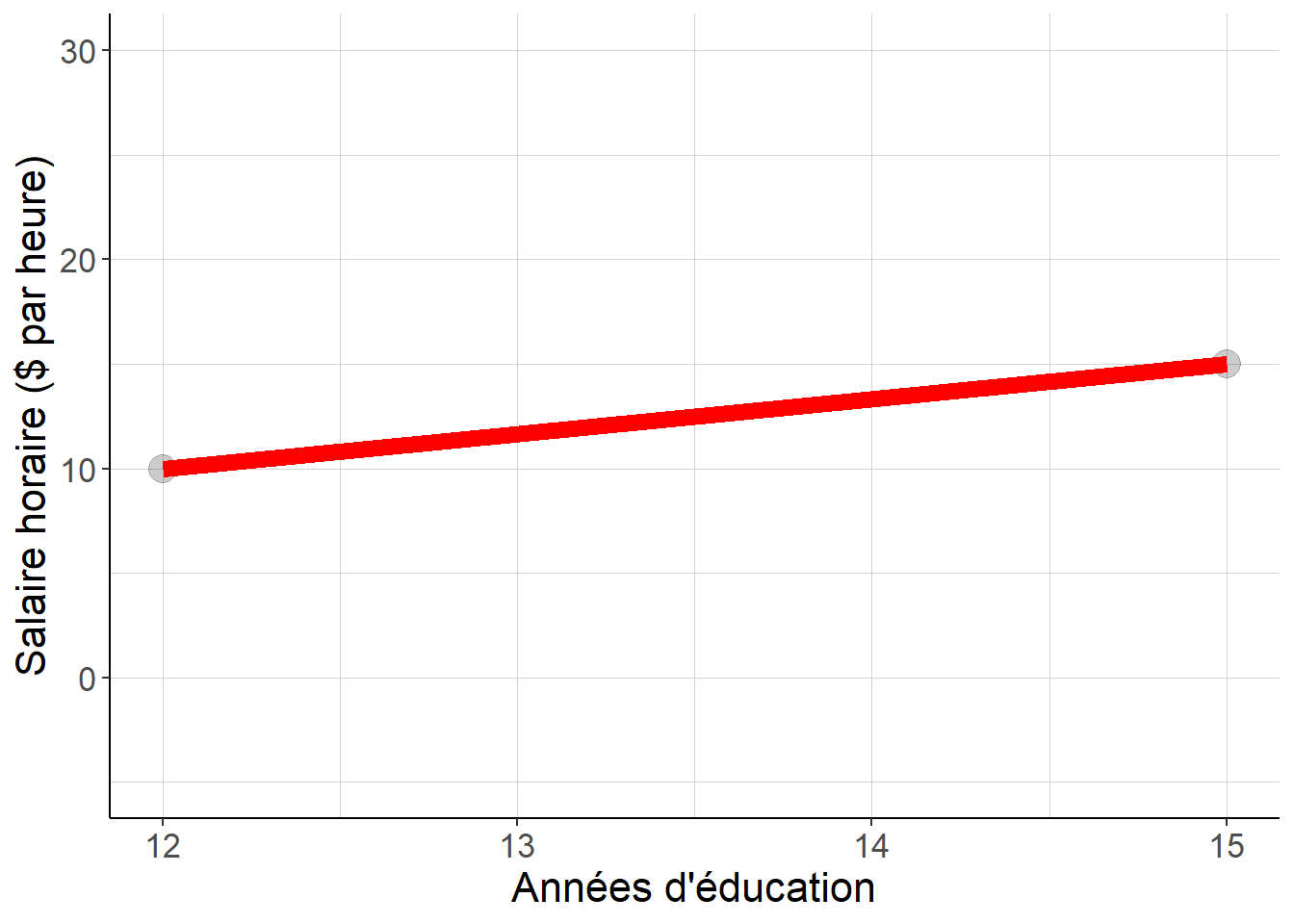
Figure 2.3: Lorsque le couple variable indépendante-variable dépendante ne prend que deux valeurs distinctes, il est facile de calculer la valeur de la pente de la droite qui passe par les deux points correspondants. Cette droite est la même que la droite de régression.
#On vérifie enfin que la droite de régression s'identifie à cette droite
reg<-lm(salaire~education,
data=fict_education_salaire)
all.equal(as.numeric(reg$coefficients["(Intercept)"]),
-10)## [1] TRUEall.equal(as.numeric(reg$coefficients["education"]),
5/3)## [1] TRUEComment passer de ce résultat au calcul du coefficient dans le cas réel de la population des salariés étatsuniens, dans laquelle il existe davantage que deux valeurs possibles pour l’éducation, et où on rencontre une grande variété de niveaux de salaires pour chacun de ces niveaux d’éducation ? Une approche naïve pourrait être de choisir aléatoirement deux salariés, puis de réaliser la comparaison précédente en prenant comme valeurs les valeurs des variables d’éducation et de salaire pour ce couple d’individus. La lectrice ou le lecteur qui a développé son intuition statistique préférera effectuer cette procédure de nombreuses fois, et faire la moyenne des résultats obtenus dans l’espoir de mieux approcher une quantité qui concerne bien toute la population des salariés étatsuniens et non un seul couple.
Il est en fait possible de montrer que pour ce qui concerne le coefficient de la variable d’éducation, il revient au même (i) d’appliquer la méthode des moindres carrés ordinaires et (ii) de faire la moyenne des pentes des droites passant par les points correspondants à tous les couples de salariés possibles dans la population des salariés étatsuniens – à condition que ces salariés n’aient pas le même niveau d’éducation –, en pondérant par le carré de l’écart entre leurs niveaux d’éducation. En d’autres termes, effectuer une régression linéaire simple équivaut à faire un grand nombre de comparaison deux à deux de salariés dont le niveau d’éducation diffère.
Le fragment de code suivant illustre ce fait à partir des données du CPS.
library(AER,
quietly=TRUE)
library(data.table,
quietly=TRUE)
library(ggplot2,
quietly=TRUE)
library(stringr,
quietly=TRUE)
#On charge dans un premier temps les données du CPS 1985
data("CPS1985")
CPS<-data.table(CPS1985)
#On estime la régression du salaire horaire sur l'éducation
reg_wage_educ<-lm(wage~education,
data=CPS)
reg_wage_educ##
## Call:
## lm(formula = wage ~ education, data = CPS)
##
## Coefficients:
## (Intercept) education
## -0.7460 0.7505#On crée tous les couples de points possibles
CPS$key<-1
CPS_couple<-merge(CPS[,c("key","wage","education")],
CPS[,c("key","wage","education")],
by="key",
allow.cartesian=TRUE)
#On calcule la pente pour chacun d'entre eux lorsque le niveau d'éducation
# diffère
CPS_couple[education.x!=education.y,
pente:=(wage.x-wage.y)/(education.x-education.y)]
#On calcule le carré de l'écart d'éducation
CPS_couple[,
carre_ecart_educ:=(education.x-education.y)^2]
#On estime enfin la moyenne pondérée des pentes
pente_moyenne<-CPS_couple[,
list(sum(pente*carre_ecart_educ,
na.rm=TRUE)/
sum(carre_ecart_educ))]
#On peut enfin comparer les résultats des deux approches
all.equal(as.numeric(reg_wage_educ$coefficients["education"]),
as.numeric(pente_moyenne))## [1] TRUE#Pour visualiser on commence par passer la table des couples de point en format
# long, mais avant ça on va échantilloner un petit nombre de couples
# représenter les segments qui relient tous les couples de points sur la même
# figure est illisible)
CPS_couple[,
couple_id:=rownames(CPS_couple)]
CPS_couple_sample<-CPS_couple[sample.int(n = .N, size = 10000)]
CPS_couple_long<-merge(melt(CPS_couple_sample[education.x>education.y,
c("education.x",
"education.y",
"couple_id")],
measure.vars=c("education.x",
"education.y"),
variable.name="indiv_id",
value.name="education")
[,
indiv_id:=str_replace(indiv_id,"education.","")],
melt(CPS_couple_sample[education.x>education.y,
c("wage.x",
"wage.y",
"couple_id")],
measure.vars=c("wage.x",
"wage.y"),
variable.name="indiv_id",
value.name="wage")
[,
indiv_id:=str_replace(indiv_id,"wage.","")],
by=c("couple_id",
"indiv_id"))
ggplot(data=CPS_couple_long,
aes(x=education,
y=wage,
group=couple_id))+
theme_classic()+#supprime l'arrière-plan gris par défaut
coord_cartesian(ylim=c(-5,30))+#choix d'échelle des axes
ylab("Salaire horaire ($ par heure)")+#titre des axes
xlab("Années d'éducation")+
theme(text=element_text(size=16),#taille du texte
strip.text.x = element_text(size=16),
panel.grid.minor = element_line(colour="lightgray",
linewidth=0.01),#grille de lecture
panel.grid.major = element_line(colour="lightgray",
linewidth=0.01))+
geom_line(alpha=0.1)+
geom_line(color="red",
linewidth=3,
data=CPS_couple_long,
aes(x=education,
y=reg_wage_educ$coefficients["(Intercept)"]+
reg_wage_educ$coefficients["education"]*education))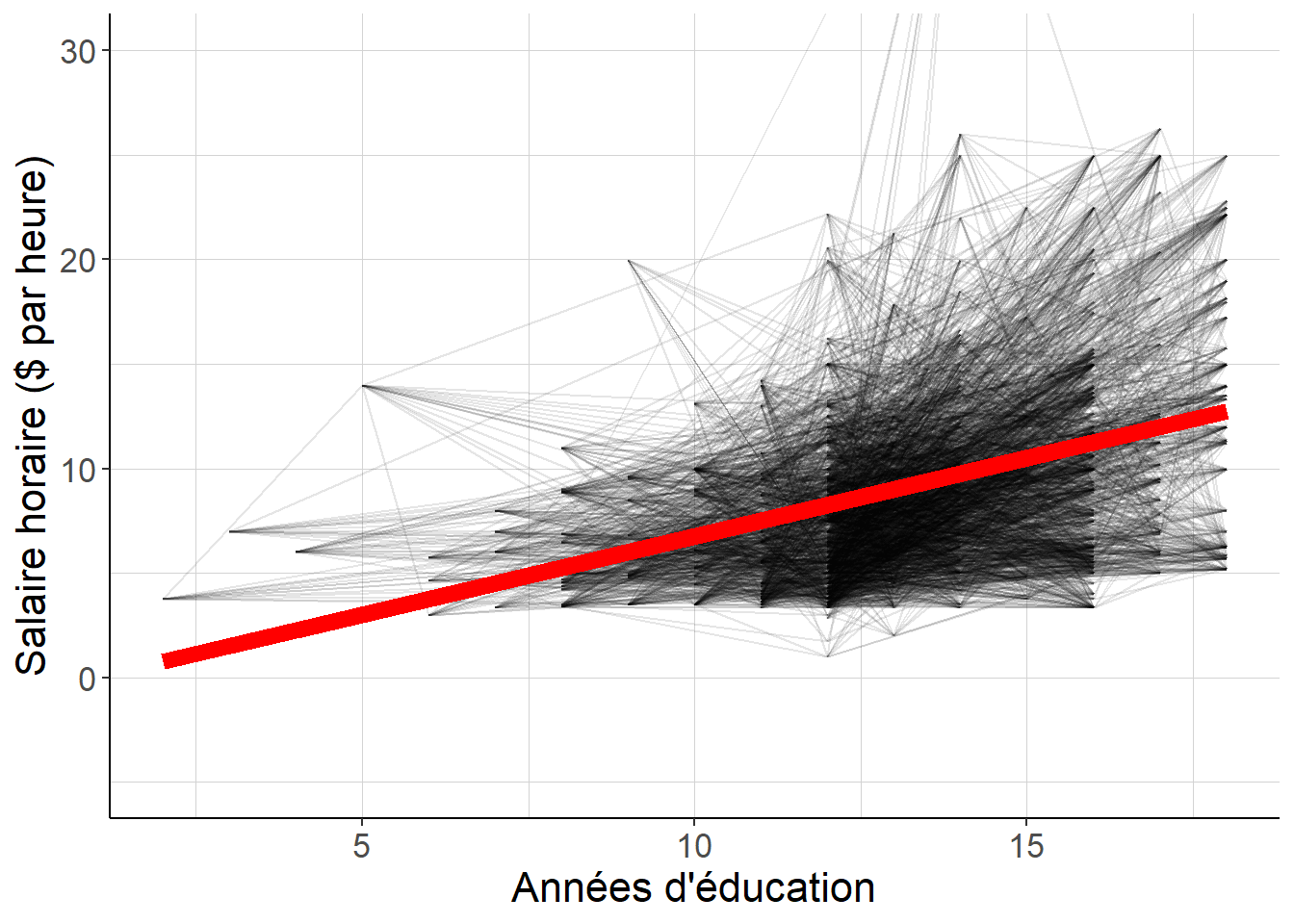
Figure 2.4: La pente de la droite de régression est une moyenne pondérée des pentes des droites qui rejoignent tous les couples de points possibles dont les valeurs de la variable indépendante diffèrent (seul un échantillon aléatoire de 10 000 couples est représenté ici), avec des poids qui donnent davantage d’importance aux couples pour lesquels les valeurs de la variable indépendante sont les plus éloignées.
Ce résultat peut s’étendre à un cas beaucoup plus général que celui de cet exemple.
À retenir
Dans le cas où l’on considère la régression d’une variable dépendante sur une unique variable indépendante, pour le calcul de la pente de la droite de régression, il revient au même d’appliquer la méthode des moindres carrés ordinaires, ou de (i) calculer la pente de la droite passant par les points représentants tous les couples possibles dans la population d’intérêt et (ii) calculer la moyenne de ces pentes avec des poids qui donnent plus d’importance aux valeurs les plus fréquentes dans la population d’intérêt et aux couples dont les valeurs de la variable indépendante diffèrent le plus.
La lectrice ou le lecteur intéressé par une preuve de ce résultat se reportera à l’Annexe A.5.
Il faut noter que l’approche proposée est beaucoup moins efficace en terme de calcul que la méthode des moindres carrés ordinaires ! En effet, par exemple dans le cas du CPS, il faut considérer \(534 \times 534 = 285156\) calculs distincts de pentes dont on fait ensuite la moyenne. Sur ce jeu de données qui n’est pas très massif, cela reste réalisable avec un ordinateur assez ordinaire, mais pour des observations beaucoup plus nombreuses cela peut vite poser des problèmes.
Le fragment de code suivant reproduit le travail précédent en comparant les temps d’exécution des deux méthodes.
library(AER,
quietly=TRUE)
library(data.table,
quietly=TRUE)
library(ggplot2,
quietly=TRUE)
#On charge dans un premier temps les données du CPS 1985
data("CPS1985")
CPS<-data.table(CPS1985)
#On estime la régression du salaire horaire sur l'éducation
system.time(
reg_wage_educ<-lm(wage~education,
data=CPS))## utilisateur système écoulé
## 0 0 0methode_pentes<-function(cle){
#On crée tous les couples de points possibles
CPS$key<-cle
CPS_couple<-merge(CPS[,c("key","wage","education")],
CPS[,c("key","wage","education")],
by="key",
allow.cartesian=TRUE)
#On calcule la pente pour chacun d'entre eux lorsque le niveau d'éducation
# diffère
CPS_couple[education.x!=education.y,
pente:=(wage.x-wage.y)/(education.x-education.y)]
#On calcule le carré de l'écart d'éducation
CPS_couple[,
carre_ecart_educ:=(education.x-education.y)^2]
#On estime enfin la moyenne pondérée des pentes
pente_moyenne<-CPS_couple[,
list(sum(pente*carre_ecart_educ,
na.rm=TRUE)/
sum(carre_ecart_educ))]
}
system.time(methode_pentes(1))## utilisateur système écoulé
## 0.02 0.02 0.03